In the public cloud parlance, consumers never provision to a specific server, instead they provision to a pool of infrastructure within a geographical region or data center. You would find this pattern in AWS, where you select Availability Zones or in Oracle Cloud, where you select the desired Data Center.
EM12c’s private database cloud follows a similar paradigm. It offers a two tier hierarchy in PaaS Infrastructure Zones, and Software Pools.
PaaS Infrastructure Zone (or Zone)
Zone is a logical grouping of cloud infrastructure resources (like servers, network, storage, etc) based on QOS, functional, departmental or geographic boundaries. For example, Finance Zone, East Coast Zone, etc. Cloud users or consumers provision into a Zone. A Zone is also used to enforce access control and chargeback/showback.
Database Software Pool (or Pool)
A group of homogeneous clustered or non-clustered database resources exhibiting common characteristics. For example,
– Pool of 11.2 Database Oracle Homes (for dedicated databases)
– Pool of 12c Container Databases (for PDBs)
Okay now that we have covered some theory, lets take an example and walk through it. Our goal to offer a database service that is highly available and redundant across multiple data centers. This image below captures the situation well.
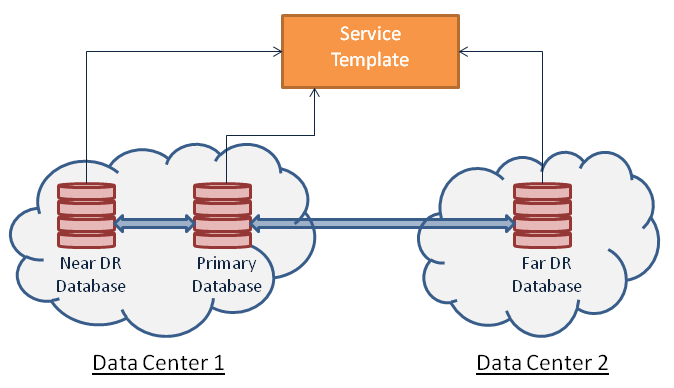
So lets get modeling.
A. Modeling Zones
1. We have two data centers – say one on the East Coast and the other on the West Coast. With this information, we could model two Zones based on the location dimension – East Coast Zone and West Coast Zone. As easy as this sounds, i don’t think putting all your hardware resources in a single grouping makes much sense.
2. Its likely that we have servers from different vendors, with different architectures, etc. Assume we own a few Exadata, some commodity servers, some SPARC servers, some VMs, etc. To accommodate this, we can update our model with the hardware dimension – East Coast-Exadata Zone, East Coast-Commodity Zone, East Coast-Sparc Zone, etc.
3. Now typically, hardware is rolled out to host applications, databases, etc. Applications have a lifecycle, they start in the development environment, then move to test, stage, performance, and finally production. Separate hardware is allocated for each of these environments, each with different characteristics – performance, cost, redundancy, etc Again, we can update our model with this new lifecycle dimension – East Coast-Exadata-Development Zone, East Coast-Exadata-Production Zone, etc
It is important to note, that all of the above dimensions are derived based on my experience with a bunch of customers. You are not required to use all of them, and it always helps to keep things simple. Lets look at pools next.
B. Modeling Pools
Pools are more software and platform centric and thus can be modeled based on various dimensions. Common dimensions are:
- Service Type: EM supports 3 service types – database, schema, and pluggable databases
- Version: This is the database software / Oracle home version
- Platform: This corresponds to operating systems like linux x86, solaris, hp-ux, etc
- High Availability: This represents if the infrastructure is RAC or SI (single instance)
- Disaster Recovery: Indicates if the pool will be used to host standby databases or just primary
So the naming format for Pools could be like this: <Service_Type>-<Version>-<Platform>-<HA>-<DR> Some examples: DB-11204-linux-RAC, DB-11204-linux-SI-STANDBY, PDB-12102-RAC, etc
Again, as i said before these are mere suggestions, and it is really up to you to decide which works best for you.
Lets come back to our example from above. If i try to implement the resource model so as to deploy a highly available and redundant database service, it would look something like this:

The zone name should indicate its composition. In the pool name, i skip the platform part since i am using Exadata and hence i assume Linux automatically. If you are using VMs or commodity hardware you may want to specify the platform as well. So my pools are composed of GI clusters deployed on Exadata compute nodes and the DB Oracle home pre-provisioned. Note a pool can contain multiple clusters. At the time of provisioning, the placement algorithm ensures that the requested database is created on a cluster with least utilized nodes. This is the power of automation provided by EM 12c.
In summary, with the EM12c resource model, cloud providers have the ability to organize and manage their infrastructure the way they would like, while keeping the consumer experience simple and intuitive.
References:

Pingback: https://adeeshfulay.wordpress.com/2015/03/25/oracle-private-database-cloud-understanding-the-resource-model/
Pingback: Cloud Privé : Le Modèle de ressource DBaaS d'Oracle
Pingback: Cloud Privé : Le Modèle de ressource DBaaS d’Oracle | Bastien Leblanc