This is a repost of my original blog on robin systems website.
Container-based virtualization and microservice architecture have taken the world by storm. Applications with a microservice architecture consist of a set of narrowly focused, independently deployable services, which are expected to fail. The advantage – increased agility and resilience. Agility since individual services can be updated and redeployed in isolation. While given the distributed nature of microservices, they can be deployed across different platforms and infrastructures, and the developers are forced to think about resilience from the ground up instead of as an afterthought. These are the defining principles for large web-scale and distributed applications, and web companies like Netflix, Twitter, Amazon, Google, etc have benefitted significantly with this paradigm.
Add containers to the mix. Containers are fast to deploy, allow bundling of all dependencies required for the application (break out of dependency hell), and are portable, which means you can truly write your application once and deploy it anywhere. Microservice architecture and containers, together, make applications that are faster to build and easier to maintain while having overall higher quality.

Image borrowed from Martin Fowler’s excellent blog: http://martinfowler.com/articles/microservices.html
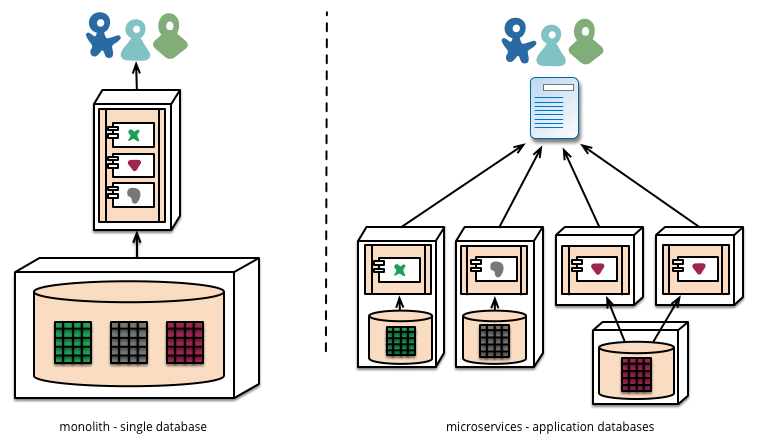
A major change forced by microservice architecture is decentralization of data. This means, unlike monolithic applications which prefer a single logical database for persistent data, microservices prefer letting each service manage its own database, either different instances of the same database technology, or entirely different database systems.
Unfortunately, databases are complex beasts, have strong dependence on storage, have customized solutions for HA, DR, and scaling, and if not tuned correctly will directly impact application performance. Consequently, the container ecosystem has largely ignored the heart of most applications: storage, and thus limit the benefits of container-based microservices due to the inability to containerize stateful & data heavy services like databases.
Majority of the container ecosystem vendors have mostly focussed on stateless applications. Why? Stateless applications are easy to deploy and manage. For example, its ability to respond to events by adding or removing instances of a service without needing to significantly change or reconfigure the application. For stateful applications, most container ecosystem vendors have focussed on orchestration, which only solves the problem of deployment and scale, or existing storage vendors have tried to retrofit their current solutions for containers via volume plug-ins to orchestration solutions. Unfortunately this is not sufficient.
To dive deeper into this, let’s take the example of Cassandra, a modern NoSQL database, and look at the scope of management challenges that need to be addressed.
Cassandra Management Challenges
While poor schema design and query performance remains as the most prevalent problem, it is rather application and use case specific, and requires an experienced database administrator to resolve. In fact, i would say most Cassandra admins, or any DBA for the matter, enjoy this task and pride themselves at being good at it.
The management tasks which Database admins would rather avoid and have automated are:
- Low utilization and lack of consolidation
- Complex cluster lifecycle management
- Manual & cumbersome data management
- Costly scaling
Let’s look at these one by one.
1. Low utilization and lack of consolidation
Cassandra clusters are, typically, created per use-case or SLA (read intensive, write intensive). In fact, the common practice is to give each team its own cluster. This would be an acceptable practise if clusters weren’t deployed on dedicated physical servers. In order to avoid performance and noisy neighbor issues, most enterprises stay away from virtual machines. This unfortunately means that underlying hardware has to be sized for peak workloads, leaving large amounts of spare capacity and idle hardware due to varying load profiles.
All this leads to poor utilization of infrastructure and very low consolidation ratios. This is a big issue for enterprises on both – on-premise and in the cloud.
Underutilized servers == Wasted money.
2. Complex Cluster Lifecycle Management
Given the need for physical infrastructure (compute, network, and storage), provisioning Cassandra clusters on premise can be time consuming and tedious. The hardest thing about this activity is estimating the read and write performance that will be delivered by the designed configuration, and hence often involves extensive schema design and performance testing on individual nodes.
Besides initial deployment, enterprises also have to cater to node failures. Failures are the norm, and have to be planned for from the get go. Node failures can be temporary or permanent and can be caused due to various reasons – hardware faults, power failure, natural disaster, operator errors, etc. While Cassandra is designed to withstand node failures, it still has to be resolved by adding replacement nodes, and it poses additional load on the remaining nodes for data rebalance – post failure and again post addition of new nodes.
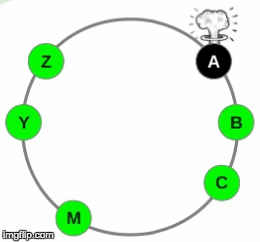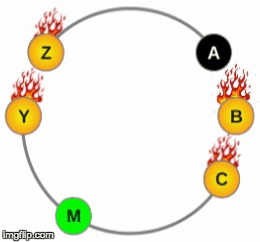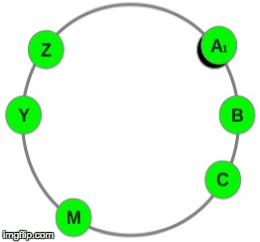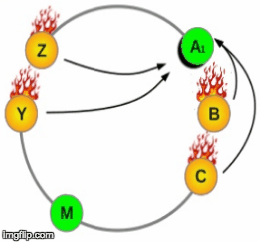
1. Node A fails
2. Other nodes take on the load of node A
3. Node A is replaced with A1
4. Other nodes are loaded again as they stream data to node A1
3. Manual Data Management
Unlike traditional databases like Oracle, Cassandra does not come with utilities that automatically backup the database. Cassandra offers backup in terms of snapshots and incremental copies, but they are quite limited in features. Most notable limitations of snapshots are:
- Use hard-links to store point-in-time-copies
- Use the same disk as data files (compaction makes this worse)
- Are per node
- Do not include Schema backup
- No support for off-site relocation
- Have to be removed manually
Similarly, data recovery is fairly involved. Data recovery can be performed for two reasons:
- to recover database from failures. For example, in case of data corruption, loss of data due to an incorrect `truncate table`, etc
- to create a copy of it for other uses. For example, to create a clone for dev/test environments, to test schema changes, etc.
Typical steps to recover a node from data failures

In order to optimize for space used for backups, most enterprises will retain last 2 or 3 backups on the server but will move the rest to a remote location. This means based on the data sample needed, you maybe be able to restore locally on the server server or have to move files around from a remote source.
While Datastax Enterprise edition does provide notion of scheduled backups via OpsCenter, it still involves careful planning and execution.
4. Costly Scaling
With Cassandra’s ability to scale linearly, most administrators are quite accustomed to adding nodes (or scale out) to expand the size of clusters. With each node you gain additional processing power and data capacity. But while node addition is required to cater to steady increase in database usage, how does one handle transient spikes?
Let’s look at a scenario. Typically, once a year, most retail enterprises will go through the planning frenzy for Thanksgiving. Unfortunately, post that event, majority of the infrastructure would be idle or requires administrators to break the cluster and repurpose it for other uses. Wouldn’t it be interesting if there was a way to simply add/remove resources dynamically and scale the cluster up/down based on transient load demands?
Summary
Many enterprises have experimented with docker containers and open source orchestrators like mesos and kubernetes, but they soon discover that these tools along with their basic storage support in volume plugins only solve the problem of deployment and scale, but are unable to address challenges with container failover, data and performance management, and the ability to take care of transient workloads. In comes Robin Systems.
Robin is a container-based, application-centric, server and storage virtualization platform software which turns commodity hardware into a high-performance , elastic, and agile application/database consolidation platform. In particular, Robin is ideally suited for data-applications such as databases and Big data clusters as it provides most of the benefits of hypervisor-based virtualization but with bare-metal performance (up to 40% better than VMs) and application-level IO resource management capabilities such as minimum IOPS guarantee and max IOPS caps. Robin also dramatically simplifies data lifecycle management with features such as 1-click database snapshot, clones, and time-travel.
Join us for a webinar on Thursday, August 25 10am Pacific / 1pm Eastern to learn about how Robin’s converged, software-based infrastructure platform can make Cassandra management a breeze by addressing all aforementioned challenges.